
This is second post in this series. See Table of Content.
SubSync is written in Python with custom native module compiled from C++ (named gizmo). During synchronization pipeline similar to this is constructed.
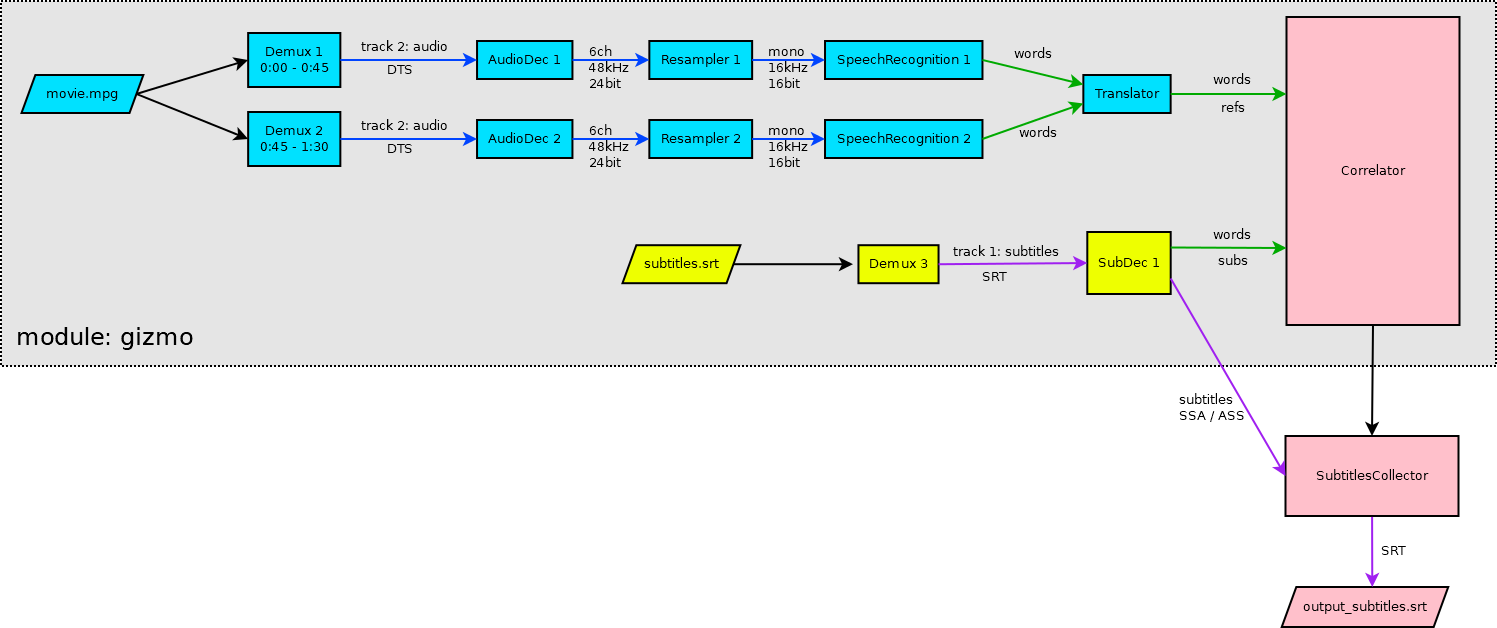
While the majority of blocks are part of the gizmo module, pipeline is constructed from the Python code, in subsync/synchro.py. There are three main parts of the pipeline:
- subs extractor (yellow blocks),
- refs extractor (blue blocks),
- correlator (pink blocks).
Subs and refs in this context means words with timestamps produced from your subtitle file (subs) or video that you are synchronizing with (refs).
Subs and refs extraction is done using FFmpeg library components wrapped as C++ objects. Demux (gizmo/media/demux.cpp) is reading input file and extracting single track. If this is audio track, it is decoded by AudioDec (gizmo/media/audiodec.cpp) and converted to the format suitable for speech recognition engine with Resampler (gizmo/media/resampler.cpp). Speech recognition is done via PocketSphinx library wrapped in SpeechRecognition class (gizmo/media/speechrec.cpp). It produces timestamped words annotated with score (floating point value between 0 and 1). This structure is named Word (gizmo/text/words.h#L8)
Similar Words are produces by SubDec (gizmo/media/subdec.cpp), which is used to decode input subtitles. In this case, score is always set to 1.
SubDec is also outputting subtitles in SSA/ASS format, which is FFmpegs internal format for subtitles. They are collected by SubtitlesCollector (subsync/subtitle.py#L57).
Reference words are translated by the Translator (gizmo/text/translator.cpp). It simply tries to lookup in its dictionary every word that is similar enough (using distance function) to the input word. It outputs corresponding translations from dictionary in form of Words with score reduced according to calculated distance. Translator is used only when the language of subtitles is different than the language of references.
Each extraction job is done in separate thread controlled by Extractor object (gizmo/extractor.cpp). It is native thread (as opposed to Python thread). In example above there are three extracting threads, one for subs and two for refs. Words are pushed to Correlator (gizmo/correlator.cpp) which runs in its own native thread by queue (gizmo/text/wordsqueue.h). Correlator calculates two values: delay and speed change which is applied to subtitles gathered by SubtitleCollector. Correlation algorithm will be described in my next post in this series.
Single instance of Translator is used in several threads. It is safe since its pushWord method has no side effects.
Refs are usually extracted with several Extractor threads, each processing different range of timestamps. In this approach we get words from different locations almost immediately which helps Correlator to produce initial synchronization faster and more accurately. Also performance-wise its usually optimal to run one PocketSphinx instance for physical CPU core.
In case when refs are generated from subtitles as well, refs pipeline looks similar to subs one.
In next post I will discuss correlation algorithm in details.