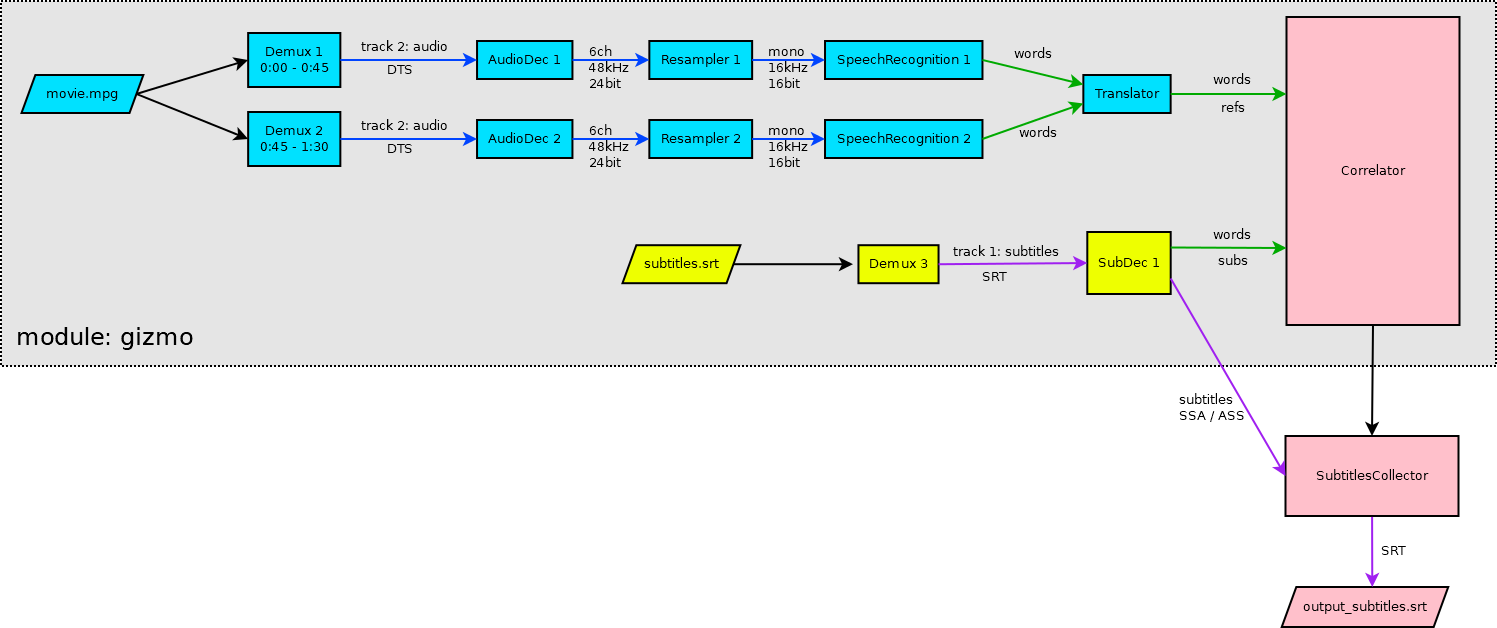
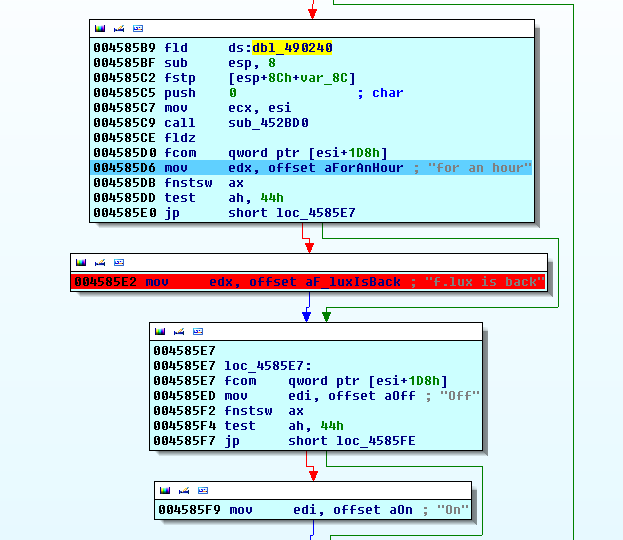
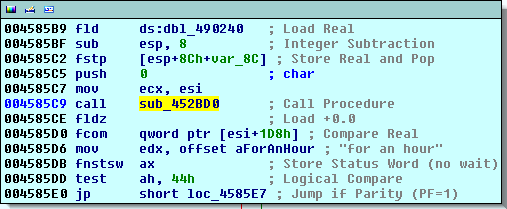
TL/DR: I’ve fixed Maya’s firmware to work better under Linux: Audiotrak-Maya-U5-firmware-mod.zip
Part 1: whats broken
Maya U5 is an USB sound card with 5.1 channels support. It has pretty decent sound quality to price ratio. I bought one to use it with my Windows computer. And under Windows it works great.
Then, one day I tried to use it under Linux. As you probably guessed – it didn’t went well. System recognized this device as stereo card, sound went down randomly, volume control was not always working. Audiotrak supports only Windows and OSX, but since this is standard USB audio device it should run under everything.
So of course I asked Google for help, and found firmware that should work. It was better – system detects proper 5.1 device. But other issues still occur.
My second step was to check official website for newer firmware updates. Well, there is one. Great! Well, actually not that great. My system tells me again that I have only two audio channels. Going back to previous firmware. Except firmware flasher attached with older firmware won’t flash my updated card.
Ok, lets compare this two firmware archives. It looks like only four files is changed: flasher exe and dll, VIAFwUpd.ini and one of the bin files. I bet it is the firmware itself. But lets check the ini first.
[DFU]
Firmware=VT1728_20121101_v0.61_0102_05_Release10_Gyrocom_withQsound.BIN
Yep, our firmware blob. And yes, after I’ve changed it to point to the older firmware bin, I can flash it with the new loader. Great work, we are where we started.
Ok, go back to Linux, lets check what kernel knows about this device
$ lsusb -vd 040d:3401
Bus 001 Device 003: ID 040d:3401 VIA Technologies, Inc.
Device Descriptor:
bLength 18
bDescriptorType 1
bcdUSB 2.00
bDeviceClass 0 (Defined at Interface level)
bDeviceSubClass 0
bDeviceProtocol 0
bMaxPacketSize0 64
idVendor 0x040d VIA Technologies, Inc.
idProduct 0x3401
bcdDevice 0.61
iManufacturer 1
iProduct 2
iSerial 0
bNumConfigurations 1
Configuration Descriptor:
bLength 9
bDescriptorType 2
wTotalLength 574
bNumInterfaces 4
bConfigurationValue 1
iConfiguration 0
bmAttributes 0xa0
(Bus Powered)
Remote Wakeup
MaxPower 500mA
Interface Descriptor:
bLength 9
bDescriptorType 4
bInterfaceNumber 0
bAlternateSetting 0
bNumEndpoints 0
bInterfaceClass 1 Audio
bInterfaceSubClass 1 Control Device
bInterfaceProtocol 0
iInterface 0
AudioControl Interface Descriptor:
bLength 10
bDescriptorType 36
bDescriptorSubtype 1 (HEADER)
bcdADC 1.00
wTotalLength 205
bInCollection 2
baInterfaceNr( 0) 1
baInterfaceNr( 1) 2
(...)
AudioControl Interface Descriptor:
bLength 14
bDescriptorType 36
bDescriptorSubtype 4 (MIXER_UNIT)
Warning: Descriptor too short
bUnitID 10
bNrInPins 3
baSourceID( 0) 1
baSourceID( 1) 7
baSourceID( 2) 19
bNrChannels 6
wChannelConfig 0x003f
Left Front (L)
Right Front (R)
Center Front (C)
Low Freqency Enhancement (LFE)
Left Surround (LS)
Right Surround (RS)
iChannelNames 0
bmControls 0x00
bmControls 0x00
bmControls 0x0a
iMixer 36
(...)
There are errors in the USB descriptors. Terrific.
Ok, I found something called Thesycon USB Descriptor Dumper – very handy tool. And it told me interesting things.
Information for device MAYA U5 (VID=0x040D PID=0x3401):
*** ERROR: Descriptor has errors! ***
(...)
Endpoint Descriptor (Audio/MIDI):
------------------------------
0x07 bLength
0x05 bDescriptorType
*** ERROR: Invalid descriptor length 0x07
Hex dump:
0x07 0x05 0x01 0x09 0x40 0x02 0x01
(...)
Endpoint Descriptor (Audio/MIDI):
------------------------------
0x07 bLength
0x05 bDescriptorType
*** ERROR: Invalid descriptor length 0x07
Hex dump:
0x07 0x05 0x01 0x09 0x60 0x03 0x01
Yeah, more errors (this error is repeated 7 times for every Audio/MIDI endpoint).
Since I have never done anything more complex with USB descriptors than looking at lsusb output, at this point I had to read a lot. There is official USB documentation here, there are also more approachable descriptions like this and that. Anyway, after some heavy reading I was able to confirm that some descriptors were broken. Probably the mixer descriptor was the problem. There is some kind of array that should map inputs to outputs, but it is truncated. Truncated MIDI descriptors also could make some trouble, but since I rarely play any MIDI, it is not priority for me.
Ok, lets look inside the device. There is VIA Vinyl™ VT2021 codec and VIA VT1728A CPU. It is hard to find anything about this chip more that it is 8032 MCU. Which is something like 8051 with extra peripherals. But wait, there is something similar. VT1620A looks like older brother of this chip. Maybe it is not full spec PDF, but it is some starting point. And IDA handle 8032 assembly.
Part 2: lets fix it
USB configuration descriptor followed by other descriptors could be found at offset 0x15ec (in firmware image release F). My first attempt was to erase MIDI endpoints. Unfortunately, this bricked the box. Flasher stopped to recognise the device.
After second examination of the board, I found 8-pin IC labelled as 25VF512A. An 512 kbit SPI flash. But how to program it without proper hardware? Well, isn’t my Raspberry PI has SPI interface? After quick googling, I’ve found Flashrom. I’ve soldered 5 wires, connected them with Raspberry and was able to resurrect Maya. Back to square one.
Having working solution to unbrick the device, we could make some more intrusive (and complicated) modifications. Ideally it would be to fix every broken descriptor. To do that, we need more room than we have (some descriptors are truncated). So we need to relocate them. But where?
I dumped whole content of flash with my Raspberry. It has 64 kB, but only about 30 kB is used by the image. Rest of the space is empty. So at the end of data, there is plenty of room.
Next we need to find references to this data. 0x15ec could be found only at offset 0x1902. It is not code, and at this moment I couldn’t figure out how it is used, but since we have working backup plan, we are safe. I’ve copied descriptors at the end of image (offset 0x78a0) updated value at 0x1902 to point to the new location and zeroed descriptors data at original location. After flashing (with Audiotrak flasher) it worked!
After many tries I was able to fix mixer and MIDI endpoints. I’ve removed remote-wakeup attribute from configuration descriptor to prevent system from suspending it. Now it is usable under Linux, but still there are minor glitches. I’ve tried to fix also newest image, but could’t make 5.1 to work, so I’ve stayed with older one.
Here is modified (fixed) firmware with new loader, so it could be flashed even on devices with newer firmware.
Audiotrak-Maya-U5-firmware-mod.zip